ISSN 1884-0760
GRACE TECHNICAL REPORTS
Context-Preserving XQuery Fusion
Hiroyuki Kato
Soichiro Hidaka
Zhenjiang Hu
Keisuke Nakano
Yasunori Ishihara
GRACE-TR 2010–07
September 2010
CENTER FOR GLOBAL RESEARCH IN
ADVANCED SOFTWARE SCIENCE AND ENGINEERING
NATIONAL INSTITUTE OF INFORMATICS
2-1-2 HITOTSUBASHI, CHIYODA-KU, TOKYO, JAPAN
Context-Preserving XQuery Fusion
H. Kato1, S. Hidaka1, Z. Hu1, K. Nakano2, and Y. Ishihara3
1 National Institute of Informatics, Japan, {kato, hidaka, hu}@nii.ac.jp
2 The University of Electro-Communications, Japan,
3 Osaka University, Japan,
Abstract. XQuery is a DBPL for querying XML databases. The semantics of XQuery is context sensitive and requires preservation of document order. In this paper, we propose, as far as we are aware, the first XQuery fusion that can deal with both the document order and the context of XQuery expressions. More specifically, we carefully design a context representation of XQuery expressions based on the Dewey order encoding, develop a context-preserving XQuery fusion for ordered trees by static emulation of the XML store, and prove that our fusion is correct. Our XQuery fusion has been implemented, and all the examples in this paper have passed the system.
1
Introduction
Fusion [21, 2, 5] is a well-known technique for improving efficiency by removing un-necessary intermediate data from the computation. Although it has been applied to op-timize query languages such as SQL [3] and object query languages [5], it remains a challenge to implement fusion for XQuery optimization. This is because XQuery has
more complicated semantics [12];it is context sensitive and requires preservation of
document order. One may consider, for example, the following naive fusion
transfor-mation4(as studied in [4]).
heiE1, . . . , Enh/ei/c7→σc(E1), . . . , σc(En)5 (F)
This transformation works correctly only if the order of the XML document and the context can be ignored. However, order is an important issue in XML documents [6, 1], and various index structure for ordered trees have been developed for XML documents [20, 14, 24]. When we view an XML document as an ordered tree, an existing fusion transformation like (F) by naive elimination of element constructors does not work cor-rectly because the context, which is a navigation of newly constructed trees, is missing during the transformation.
4
Analogous to relational algebra operators,σcis used as a selection, which extracts data with their element name beingc.
<na> <lhs>
<item><a/></item> <item><b/></item> </lhs>
<rhs>
<item><c/></item> <item><d/></item> </rhs>
</na>
<sa> <lhs>
<item><c/></item> <item><d/></item> </lhs>
<rhs>
<item><a/></item> <item><b/></item> </rhs>
</sa> <sa>
(<lhs>/na/rhs/item</lhs>, <rhs>/na/lhs/item</rhs>) </sa>
Fig. 1.Source XML:S(left). XQuery expression:em(middle) and the serialized result:T(right).
Consider the simple case illustrated in Figure 1, where the queryem(the middle) is
applied to the sourceS(the left), and the targetT(the right) is obtained as the serialized
result. Let us apply the following querye1to the serializedT,
e1:let $v := (/sa/rhs, /sa/lhs) return $v/item.
Since the semantics of “axis access” by using “/” in XQuery (and XPath) requires sort-ing without duplicates in the document order, the correct result is the followsort-ing se-quence of “item” elements:
hitemihc/ih/itemi,hitemihd/ih/itemi,hitemiha/ih/itemi,hitemihb/ih/itemi.
However, for the composite querye1◦em, by unfolding the expressionem, we can get
let $t := hsai{(hlhsi/na/rhs/itemh/lhsi,hrhsi/na/lhs/itemh/rhsi)}h/sai return let $v := ($t/rhs,$t/lhs) return $v/item.
Now if we perform the calculation according to the context-insensitive fusion rule (F):
e1◦em
→ {(variable expansion for$t);(F)}
let $v := (hrhsi/na/lhs/itemh/rhsi,hlhsi/na/rhs/itemh/lhsi) return $v/item
→ {(variable expansion for$v);(F)}
(/na/lhs/item, /na/rhs/item)
then evaluating the transformed query(/na/lhs/item, /na/rhs/item)onSgives
hitemiha/ih/itemi,hitemihb/ih/itemi,hitemihc/ih/itemi,hitemihd/ih/itemi
whose order of “item” elements is different from the expected result. Furthermore, if
we consider the querye2onT:
then although the expected result of e2 to T is the “rhs” element, the result of the
transformed query frome2◦emvia similar steps above is the “lhs” element. In both
examples, the problem is caused by not having the context, which is a tree navigation
over the newly constructed XML fragment usinghsai...h/saiinem.
The problem of the existing fusion transformation lies in that the naive elimination of element constructors during the transformation does not preserve the (computation) context because element constructors construct ordered trees. This implies that elimi-nating element constructors in XQuery expressions and preserving the context of the expressions are conflicting requirements. The purpose of our work is to propose a new fusion mechanism to meet these two requirements. To this end, we should find a way to manage the context of the original expressions in developing a correct fusion transfor-mation.
While we will show the concrete solution to both examples at the end of this paper, we shall give an intuitive idea of our solution to the first example here. For two step
expressions/na/rhs/item and/na/lhs/iteminemwhich constructs the ordered tree
T, there is a fact that the items of the sequence generated by /na/rhs/item always
precede ones generated by/na/lhs/item in the ordered treeT for an arbitrary XML
store. By adding this information to these two step expressions, for givene1◦em, we
can formulate the correct XQuery expression(/na/rhs/item, /na/lhs/item)from this
information. We call this information, context.
We propose a novel context-preserving XQuery fusion for when an XML document
is modeled as an ordered tree. Our basic idea isto lift dynamic operations on XML store
to the static level of expression. Our main contributions can be summarized as follows.
– To keep track of context, we carefully design the context representation of XQuery
expressions to reflect the properties of element constructions. This enable us to stat-ically emulate newly created XML fragments — created by element constructors — in the XML store.
– We develop a context-preserving fusion for XQuery by partial evaluation and prove
the correctness of our fusion. Our fusion introduces an annotated XQuery, which is an XQuery expression with the context as an annotation, to preserve the context of the input expressions even when the element constructors are eliminated during our fusion transformation.
The paper proceeds as follows. Section 2 reviews the XQuery semantics and in-troduces value equivalent expressions to show our fusion concisely. In Section 3, we carefully design the context of XQuery expressions by extending Dewey code and its order to suite the semantics of XQuery expressions. Section 4 presents the algorithm of context-preserving fusion using the extended Dewey code and its order. We discuss related work in Section 5 and conclude the paper in Section 6.
2
XQuery Semantics
e::=$v|(e, e, ..., e)|()|e/α::τ|for $v in e return e | let $v :=e return e| htieh/ti
A query expression can be a variable $v, a sequence expression(e1, . . . , en)where
each subexpressionei is not a sequence expression, an empty sequence(), a location
step expressione/α::τwhereαis an axis which can bechild,self,parent(..), andτis a
name test which can be a tag nametor∗(an arbitrary tag), a “for”-expression, a
“let”-expression, or an element construction expressionhtieh/ti. Since we focus on newly
constructed trees that consist of XML nodes, to simplify the presentation, a constantc
is represented by “empty-element tags” likehc/i. Although constants themselves are
not nodes, they become a (text) node when they occur in an element constructor. For example, a constant “abc” is not a node i.e., this constant does not populate any ordered
trees. On the other hand, considerhai“abc”h/ai; in this expression, the constant “abc” is
a text node because the constant occurs in the element construction ofhai(...)h/ai, i.e.,
this constant is a child node of the element node ofa. We could define the semantics
of constants with such behavior, but this would make our presentation unnecessarily complex.
2.1 Sequence: Data Model in XQuery
The data model of XQuery issequences[22]. A sequence is an ordered collection of
zero or more items. One important characteristic of the data model is that sequences
areflatin the sense that a sequence never contains other sequences; if sequences are
combined, the result is always a flattened sequence. In addition, there is no distinction
between an item and a singleton sequence containing that item, i.e., we often write[a]
asaor vice versa.
We denote the empty sequence as [], non-empty sequences for example as [a,b,c],
and the concatenation of two sequencess1ands2ass1++s2. We use∈for sequence
containment in addition to set containment and[d|d∈ D∧φ(d)]for a sequence ofd
obtained by selecting them fromD, all items that satisfyφ(d).
2.2 Dewey Order Encoding and XML Store
An XML document is modeled as an ordered tree.Document orderin an XML
docu-ment is a total order defined over the nodes in a tree, and this order is determined by a preorder traversal of the tree. This order plays an important role in the semantics of XQuery, especially in node creation and axis accesses. An XQuery expression is evalu-ated against an XML store which contains XML fragments with their document order. This store contains fragments that are created as intermediate results, in addition to the initial XML documents [12].
Dewey order encoding of XML nodes is a lossless representation of a position in the document order [14, 20]. In Dewey order, each node is represented by a path from
a root using ‘.’ : (1) a root node is encoded byr ∈ R, whereRis a countably infinite
set of special codes; (2) say that a nodeais then-th child of a nodeb; then the Dewey
code ofa,did(a), isdid(b).n. The fact that the relative order of nodes in distinct trees
Dewey codes begin with different codes, it implies that the two nodes are in different ordered trees. By using Dewey order encoding, one can easily compute axis relations.
For example,ancestor(d1, d2)holds whend1has the formd2.n1.n2.· · ·.nk.
LetT be a set of symbols for element names, andDbe a countably infinite set of
Dewey codes on which a strict partial order<and the equality=is defined.
Definition 1 (Simple XML Store).A simple XML store is a pairSt = (D, ν), where (a)D is a finite subset ofDand (b)ν is a partial functionν : D 7→ T that maps a Dewey code to its element name.
For instance, the store of the sourceS in Figure 1 is defined asSt0 = (D0, ν0),
whereD0={s, s.1, s.1.1, s.1.1.1, s.1.2, s.1.2.1, s.2, s.2.1, s.2.1.1, s.2.2, s.2.2.1}and
ν0(s) = na,ν0(s.1) = lhs,ν0(s.2) =rhs,ν0(s.1.1) = ν0(s.1.2) = ν0(s.2.1) =
ν0(s.2.2) =item,ν0(s.1.1.1) =a,ν0(s.1.2.1) =b,ν0(s.2.1.1) =c,ν0(s.2.2.1) =
d. In what follows, we will refer to a simple XML store as an XML store. We denote
the disjoint union of two storesSt1andSt2asSt1∪St2(combiningDandν
indepen-dently).
Definition 2 (Value Equivalence, ≡(St1,St2)). Given two stores St1, St2, and two
nodes, d1 in St1 and d2 in St2, d1 and d2 are said to be value equal, denoted as
d1 ≡(St1,St2) d2, ifd1andd2refer to two isomorphic trees, i.e., there is a one-to-one
functionh : D1 7→ D2 withD1 = {d|d ∈ DSt1 ∧ancestor-or-self(d, d1)}
andD2 ={d|d ∈ DSt2 ∧ancestor-or-self(d, d2)}, such that for eachdand
d′ ∈ D
1, it holds that (1) h(d) ∈ D2, (2) ν(d) = ν(h(d)), and (3) d < d′ iff
h(d) < h(d′). This definition can be extended to the value equivalence over two
se-quences, straightforwardly.
2.3 Formal Semantics
The formal semantics of XQuery established by W3C is defined over XQuery Core, which is a subset of XQuery [23]. While XQuery Core does not have a location step expression, the reason why our target has is that (1) evaluating path expressions is more efficient than “for”-expressions [8, 18], although theoretically, it can be trans-lated into “for”-expressions; and (2) previous work on XQuery dealt with location steps [13, 10, 9]. Figure 2 shows the semantics of our target XQuery using a set of
infer-ence rules. In these rules, a judgment of the formSt;En ⊢ e ⇒ (St′, s) indicates
that the evaluation of expressioneagainst the storeSt and environmentEn(mapping
variables to values) results in a (new) storeSt′and values. The semantics of sequence
expressions, “let”-expressions and variables are straightforward. The semantics of a
“for”-expression (for $v in e1 return e2) is the concatenation of the results ofe2
evaluatedNtimes for each item in the result ofe1but withvin the environment bound
to the item in question in the result ofe1, whereN is the length of the sequence of
the result ofe1. The semantics of the element constructor (htieh/ti) and location step
(e/α::τ) are worth futher attention because they are evaluated using the document
or-der. The semantics ofhtieh/tiis as follows. A new storeSt2that contains a new root
node havingtas its name and having contents is created. The contents are the
St;En⊢()⇒(St,[])
St;En⊢e1⇒(St1, s1) · · · StN−1;En⊢eN⇒(StN, sN)
St;En⊢(e1, . . . , eN)⇒(StN, s1++. . .++sN)
St;En⊢e1⇒(St0,[d1,· · ·, dN])
St0;En+{$v7→d1} ⊢e2⇒(St1, s1) · · ·
StN−1;En+{$v7→dN} ⊢e2⇒(StN, sN)
St;En⊢for $v in e1 return e2⇒(StN, s1++· · ·++sN)
St;En⊢e1 ⇒(St1, s1) St1;En+{$v7→s1} ⊢e2⇒(St2, s2) St,En⊢let $v:= e1 return e2 ⇒(St2, s2)
St;En⊢$v⇒(St,En($v))
St;En⊢e⇒(St1, s1) a freshr∈ R
d∈DSt2 ⇒dbegins withr νSt2(r) =t
ddoSt2[d′|d′∈DSt2∧child(d′, r)] =s2 s1≡(St1,St2)s2
St;En⊢ htieh/ti ⇒(St∪St2,[r])
St;En⊢e⇒(St0,[d1,· · ·, dN])
[d′
1|d′1∈DSt0∧α(d
′
1, d1)∧νSt0(d
′
1) =τ] =s1 · · ·
[d′N|d′
N∈DSt0∧α(d
′
N, dN)∧νSt0(d
′
N) =τ] =sm
St;En⊢e/α::τ⇒(St0,ddoSt0(s1++· · ·++sm))
Fig. 2.Semantics of XQuery using the simple XML store
created root node is returned. The semantics ofe/α::τ is as follows. First,eis
eval-uated. Then, for each nodedi in its result, construct a sequencesi such that for each
contentd′
i insi,d′iis contained inSt0, andα-relation holds fordi andd′i, and the
el-ement name ofd′
i isτ. The results of these sequences are concatenated. Finally, this
sequence is sorted in the document order and duplicates are removed from it because an axis access by “/” requires sorting and duplicate elimination in the document order. This
sorting without duplicates is performed by using the functionddo(distinct-doc-order).
Value equivalent expressionsare introduced in order to prove the correctness of our fusion later.
Definition 3 (Value Equivalent Expressions).Given a storeSt, an environmentEn, and two XQuery expressionse1 ande2,e1and e2are said to be value equivalent, if the following conditions hold;St;En⊢e1⇒(St1, s1),St;En⊢e2 ⇒(St2, s2)and
s1≡(St1,St2)s2.
3
Emulating XML Stores with Extended Dewey Codes
correct fusion transformation, we should be able to emulate (keep track of) the con-text information (i.e., XML store) during the static transformation when an element is
constructed. Our idea is tolift dynamic operations on XML store to the static level of
expression, and it is based on the observation that Dewey order encoding of the result of the evaluation of an expression corresponds well to the structure of the expression.
3.1 XML Store Emulation on Expression
First, we show an important property for element constructors in terms of Dewey code: The Dewey order encoding of the result of an evaluation of an expression corresponds to the structure of the expression. This enables us to associate the static transformation world with the dynamic evaluation world by using Dewey code.
Given an element constructionhtieh/ti, we denote its relation with its result by
htieh/ti ∼rif there existSt,En,St′such thatSt;En⊢ htieh/ti ⇒(St′, r).
Property 1 (Dewey code correspondence in element construction).For an element
con-struction,htieh/ti, the following properties hold.
(i) htieh/ti ∼r, wherer∈ Randris not in the input store.
(ii)htieh/ti ∼rande∼[r1,· · · , rn]implyri =r.i.
(iii) Forhti(e1, e2)h/ti,(e1, e2)∼[r1, r2]andd1∈r1andd2∈r2implyd1< d2. (iv)ht1ie1h/t1i ∼r1andht2ie2h/t2i ∼r2implyr1=6 r2, wherer1, r2∈ R.
The above correspondence property hints that we should associate each expres-sion with a Dewey code, so that these codes can be used to keep track of context in-formation during the fusion transin-formation. For instance, for the element construction
hti($v/c,$v/a)h/ti, we may give the following Dewey order encoding to the
expres-sion:
(hti($v/c)r.1,($v/a)r.2h/ti)r
whereeddenotes thatdis the Dewey order encoding of the expressione(we will define
this formally in Section 4.)
One difficulty, however, remains in associating Dewey codes to expressions to keep the context information: how do we deal with the “for” (“let”) expressions in XQuery? We have to extend Dewey code for this purpose.
3.2 Extended Dewey Code
To be able to associate XQuery expressions with suitable context information, we
pro-pose anextended Dewey code(xD), defined by
ˆ
d::=nˆx|ǫ|[ˆd,ˆd, . . . ,ˆd] ˆ
x ::=ǫ|”.”ˆd|”#”dˆ
wheren∈(R ∪ I)withRbeing a set of special codes6andIbeing a set of integers.
It has a hierarchical structure, the same as in XQuery expressions, because xD is an
6The special code is used to exploit
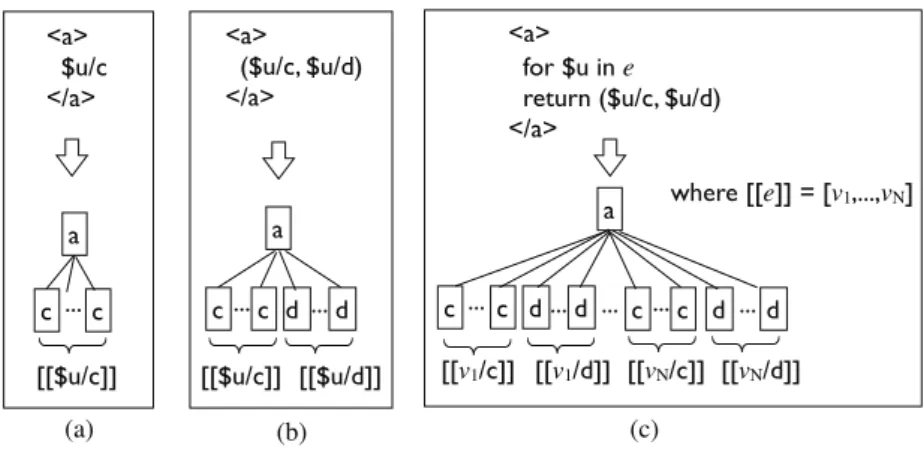
<a> ($u/c, $u/d) </a>
a
c...c d ...d
[[$u/c]] [[$u/d]] <a>
$u/c </a>
a
c ...c
[[$u/c]]
<a> for $u in e return ($u/c, $u/d) </a>
c ...c d...d ... c...c d ...d
a where [[e]] = [v1,...,vN]
[[v1/c]] [[v1/d]] [[vN/c]] [[vN/d]]
(a) (b) (c)
Fig. 3.A simple example for the document order in element creations
annotation for an XQuery expression. Here, the underlined parts are our extension, and
ǫ is used for a termination, so, every xD ends withǫ. Intuitively, the form of xD is
as follows. ǫis annotated to an expression, which does not occur inside an element
constructor. A sequence construction has the form of sequence7is used. The delimiter
“.”, which plays the same role as in the original Dewey codes, is used to represent parent-child relationships.
The delimiter “#”, which is our extension, represents the association of a “return” clause with a “for” or “let” expression and is used to resolve sortings with duplicate elimination for multiple “for” or “let” expressions that are derived from identical “for” or “let” expressions. Figure 3 (c) shows how an element is constructed with the “for”
expression(Q1).
Q1: haifor $u in e return ($u/c,$u/d)h/ai
To show the idea behind the design of our delimiter “#”, let us consider the fusion
transformation for the expression ((Q1)/d,(Q1)/c)/self ::∗. For the expressions
(Q1)/dand(Q1)/c, we can get thevalue equivalentexpressions(Q2)and(Q3),
respectively, from the XQuery semantics.
Q2: for $u in e return $u/d
Q3: for $u in e return $u/c
Now consider the following expression(Q4).
Q4: (((Q2)),((Q3)))/self::∗
7
eˆd
::=$vˆd
|(eˆd , eˆd
, ..., eˆd
)dˆ
|(eˆd /α::τ)ˆd
|(for $v in e
ˆ d
return eˆd
)ˆd
| (let$v :=e
ˆ d
return eˆd
)ˆd
|(htieˆd
h/ti)ˆd
Fig. 4.Annotated XQuery
As described in the previous section, since axis access by “/” requires sorting and
du-plicate elimination in document order, the correct transformation of(Q4)should result
in(Q5), in which two “for” expressions(Q2)and(Q3)are merged.
Q5: for $u in e return ($u/c,$u/d)
Here, we can capture the order of the two expressions in the “return” expressions by
using “#”. Thus, by encoding(Q1)into
(hai(for $u in e return ($v/c,$v/d))r.1#[1,2]h/ai)r
and encoding(Q2)and(Q3)into
(for $uin e return $v/d)r.1#2and(for $u in e return $v/c)r.1#1
we can apply the transformation to(Q5)(See Section 4), thanks to sorting on
subse-quences produced by the “for” expressions.
Returning to our extend Dewey codes, we can introduce the context position of
sort-ing and duplicate elimination overˆdin a similar way to the original Dewey code (See
Appendix A for details). Therefore, we can use the functionsdc sortandremove dup
for sorting and duplicate elimination, respectively. The difference from the sorting of the original Dewey code is in merging two extended codes sharing the same prefix until
they reach#. For instance, sorting [r.1#2, r.1#1] results in [r.1#[1,2]].
4
XQuery Fusion
This section describes our algorithm for automatic fusion of XQuery expressions so that unnecessary element constructions can be correctly eliminated. Basically, we will focus on fusing the following subexpression,
e/α::τ
so that unnecessary element constructions in the query expression ineare eliminated
under the context of “selection” byα::τ.
We add annotations of the extended Dewey codes to the XQuery expression (Figure 4). We sometimes omit the annotation if it is clear from the context. To simplify our presentation, we will assume that there is a global environment for storing all annotated expressions during our fusion transformation, and a function
getExpGlobal(r)
peval () Θ= ()[]
peval $v Θ=
Θ($v)if $v is letvar
$v otherwise (PEVR) peval (e1, ..., eN) Θ= lete′i=peval ei Θ
di=extract dc(e′i) in flatten ((e′
1, ..., e′N)[d1,..,dN])
(PESEQ)
peval (e/child::τ) Θ=Fc(peval e Θ)τ (PECSTP)
peval (e/self::τ) Θ=Fs(peval e Θ)τ (PESSTP)
peval (e/parent::τ) Θ=Fp(peval e Θ)τ (PEPSTP)
peval (let$v :=e1 return e2) Θ= lete′1 =peval e1 Θ
e′
2 =peval e2 (Θ∪ {$v7→(e′1,let)}) ine′
2 (PELET)
peval (for $v in e1 return e2) Θ= lete′1 =peval e1 Θ
e′
2 =peval e2 (Θ∪ {$v7→(e′1,for)})
d=extract dce′
2
in(for $vin e′1 return e′2)#d (PEFOR) peval (htieh/ti) Θ= lete′=peval e Θ
a freshr∈ R in dc assignhtie′h/tir
(PEEC)
Fig. 5.Fusion by partial evaluation
4.1 Fusion Transformation
Figure 5 summarizes our fusion transformation on XQuery expressions. Fusion is
de-fined by a partial evaluation functionpeval:
peval :: e→Θ→eˆd
which accepts an XQuery expression and an environmentΘ(mapping variables bound
by “let” or “for” to expressions):
Θ::Var →(eˆd
,let|for)
and produces a more efficient XQuery expression in which subexpressions are anno-tated by the extended Dewey codes. As will be seen later, the annotation is used to keep track of information of the order and the context among expressions, and it plays an important role in our fusion transformation. When the fusion transformation is finished, we can ignore all the annotations and get a normal XQuery expression as the final result.
The definition of peval in Figure 5 is straightforward. For a variable, if it is
dc assign() r= ()[]
dc assign$v r= $vr
dc assign(e/c) r= (e/c)r (
DCSTP)
dc assign(e1, . . . , en) r= letr0=r
e′
i=dc assigneiri−1
ri=succ(extract dce′i) in(e1, . . . , en)[r1,...,rn]
(DCPSEQ)
dc assign(<t>e</t>) r= lete′=dc assigne
ir.1 in<t>e′</t>r
(DCPEC)
dc assign(for $v in e0 return e) r= lete′=dc assigne1 bs=extract dce′
in(for $v in e0 return e′)r#
bs
(DCPFOR)
Fig. 6.Dewey code propagation
group them into a new sequence annotated with Dewey codes from the results of
each element expression. Note that we useflatten to remove nested sequences (e.g.,
flatten((er1
11, e r2
12)[r1,r2], e r3
3 )[[r1,r2],r3] = (e r1
11, e r2
12, e r3
3 )[r1,r2,r3]), andextract dcto get
annotated Dewey code from an expression (i.e., extract dc ed = d). For a location
step expression e/α::τ , we perform fusion transformation to eliminate unnecessary
element constructions ineafter partially evaluatinge. We will discuss the definitions
of the three important fusion functionsFc,Fs, andFp, later. For a “let” expression, we
first partially evaluate the expressione1, and then partially evaluatee2with an updated
environment and return it as the result. We do similarly for a “for” expression except that we finally produce a new “for” expression by gluing partially evaluated results together. For an element construction, after partially evaluating its content expression
eintoe′, we create a new Dewey code for annotating this element and propagate this
Dewey code information to all subexpressions ine′(with the functiondc assign) so that
we can access (recover) this element constructor when processing the subexpressions
ofe′. It is this trick that helps to solve the problem ofe2◦emin the Introduction.
Dewey Code Propagation Propagating the Dewey code of an element construction to its subexpressions plays an important role in constructing our fusion rules, described later, for correct fusion transformation.
Figure 6 defines a functiondc assign e−r:
dc assign::eˆd →ˆd→eˆd
which is to propagate the Dewey coderinto an annotated expressioneby assigning
proper new Dewey codes toeand its subexpressions. In what follows, we will explain
some of the important equations in this definition. Note that we writee−to denote that
the Dewey code ofeis “don’t care”.
The equation (DCPSEQ) horizontally numbers sequence expressions. The function
processed expressions (e.g.,succ r.1 = r.2). (DCPEC) introduces a vertical structure
to the numbering by initiating dc assign for the subexpression e by adding “.1” to
its second parameter. The equations that needs additional attention are (DCSTP) and
(DCPFOR). In (DCSTP), it may seem unusual for dc assignnot to recurse
subexpres-sione. However, considering that the path expression itself does not introduce an
addi-tional parent-child relationship and thatdc assignalways handles expressions already
partially evaluated expressions, there is no additional chance to simplify the path ex-pression further by using the Dewey code allocated to the subexex-pression. In particular,
the characteristic equation (DCPFOR), which introduces # structure to the Dewey code,
numbers the expressioneat the return clause. Note that the second parameter of the
recursive call for eis reset to 1.bs that reflects the horizontal structure produced by
the return clause is combined with the # sign to producer#bs as the top level code
allocated to the “for” expression.
Lemma 1. From the definition ofdc assign, given an XQuery expression e, the ex-tended Dewey code assigned bydc assign e−rsatisfiesProperty1.
Fusion Rules Our fusion transformation one/α::τ is based on the three fusion rules
(functions)Fc,FsandFpin Figure 7 that respectively correspond to three axis types.
The basic procedure is as follows:
1. Extract (get) subexpressions according to the axisα;
2. Select those that produce nodes whose name is equal to the tag nameτby using a
filter;
3. Sort the remaining subexpressions according to their Dewey codes;
4. If the above sort step succeeds, remove the duplicated subexpressions and return its sequence as the result; otherwise, end fusion.
More concretely, let us consider the definition ofFc. We useget children eto get a
sequence of subexpressions that contribute to producing children of the XML document
that can be obtained by evaluatinge, and use the filter(equal toτ)function to keep
those that are equal toτ, wherefilter pxs= [x|x←xs, p x]. The resulting sequence
expression is sorted according to their Dewey codes bydc sort. This sorting may fail
since not all of the Dewey codes are comparable. If the sorting succeeds, we return a sequence expression by removing all duplicated element subexpressions; otherwise, we
end fusion by returning the original expressione/child::τ.
Our fusion transformation always terminates and is correct, as summarized by the following theorem.
Theorem 1 (Correctness of Fusion).For an XQuery expressione, ifpeval e {} =
e′d′
theneande′are value equivalent expressions.
Proof. (sketch): It is sufficient to show the correctness for location step expressions. For other expressions, it is straightforward to show the correctness by using structural in-duction on the expressions. For location step expressions, the correctness is implied by
Simple Example Fore1◦emdescribed in the introduction, our fusion functionpeval works as follows.
peval e1◦em {}
{(PECSTP);(PELET);(PEEC)}
let $t := hsai{(hlhsi/na/rhs/itemr.1.1h/lhsir.1,
hrhsi/na/lhs/itemr.2.1h/rhsir.2)[r.1,r.2]}h/sair
return let $v := ($t/rhs,$t/lhs) return $v/item
{(PELET);(PESEQ);(PECSTP);(PECSTP)}
let $v := (hrhsi/na/lhs/itemr.2.1h/rhsir.2, hlhsi/na/rhs/itemr.1.1h/lhsir.1)[r.2,r.1] return $v/item
{(PECSTP)}
remove dup (dc sort (/na/lhs/itemr.2.1, /na/rhs/itemr.1.1))
→
(/na/rhs/itemr.1.1, /na/lhs/itemr.2.1)
Fore2◦em, which is also from the introduction,pevalperforms the correct
transforma-tion.
peval e2◦em {}
{(PELET);(PESEQ);(PECSTP);(PECSTP)}
let $t := hsai{(hlhsi/na/rhs/itemr.1.1h/lhsir.1,
hrhsi/na/lhs/itemr.2.1h/rhsir.2)[r.1,r.2]}h/sair
return let $v := $t/rhs/item return $v/..
{(PELET);(PECSTP);(PEPSTP);(PEVR)}
/na/lhs/itemr.2.1/..
{(PFUSION)}
hrhsi/na/lhs/itemr.2.1h/rhsir.2
5
Related work
There are many studies on rewriting XQueries into other XQueries [11, 17, 13, 19]. The study most related to ours in the sense of eliminating redundant expressions is [11]. The authors of [11] proposed a rewriting optimization that replaces expressions which return empty sequences with () by using an emptiness detection based on static analysis. In contrast, our rewriting eliminates redundant element constructors as well.
Koch [13] and Page et al. [17] introduced some classes for composite XQuery and proposed XQuery-to-XQuery transformations over the classes of XQuery they defined. Their target queries don’t contain newly constructed nodes. In the real world, how-ever, practical expressions such as schema mapping always return newly constructed elements.
because the schema mapping that maps one element to an other element involves el-ement construction. They treat the actual reformulation algorithm as a black box. Our work attempts to open the box and exploit some of its properties.
Fusion has been extensively studied in the functional programming (FP) commu-nity [21, 2, 7, 16]. Referentially transparent FP languages allow naive fusion rules (F), as we saw in the Introduction, if the element constructor behaves like the constructors in FP. However, since the element constructor introduces a new node identity in each evaluation, thereby breaking the referential transparency, it is not directly applicable. It would be interesting to promote the identity as a first class object by using the technique described in [15], but our focus here is to perform XQuery-to-XQuery transformations, and the node identity is not a first class object in XQuery.
6
Conclusion
We proposed a new rewriting technique for XQuery fusion to eliminate unnecessary element constructions in the expressions while preserving the document order. The prominent feature of our framework is its static emulation of the XML store and as-signment of extended Dewey codes to the expressions. The result is easy construction of correct fusion transformations.
We implemented a prototype system in Objective Caml. It consists of about 4600 lines of code. Currently it works stand-alone by reading XQuery expressions from stan-dard input and produces rewritten XQueries to stanstan-dard outputs. The system is available athttp://www.biglab.org/fusion.
We believe that our approach can be generalized straightforwardly to handle the
other axes including “transitive” axes likeancestor.
Fc::e ˆ d
→τ →eˆd
Fc e
d
τ =
remove dup(e′
1, ..., e′N)ifdc sort succeeds
(ed/
child::τ)ǫ
otherwise
where(e′
1, ..., e′N) =dc sort(filter(equal toτ)(get childrene d
)) (CFUSION)
Fs::e ˆ d
→τ→eˆd
Fs e
d
τ=
remove dup(e′
1, ..., e′N)ifdc sort succeeds
(ed/
self::τ)ǫ otherwise where(e′
1, ..., e′N) =dc sort(filter(equal toτ)(get self e d
)) (SFUSION)
Fp::e ˆ d
→τ →eˆd
Fp e
dτ =
remove dup(e′
1, ..., e′N)ifdc sort succeeds
(ed/parent::τ)ǫ otherwise where(e′
1, ..., e′N) =dc sort(filter(equal toτ)(get parent e d))
(PFUSION)
get children::edˆ
→eˆd
get children$v = ($v/child::∗)ǫ
get children()[]= ()[]
get children(e1, ..., eN) =flatten ((e′1, ..., e′N)
[d1,..,dN])
where e′
i=get children ei di=extract dc(e′i) (GCSEQ) get children(e/child::en) = (e/child::en/child::∗)ǫ
get children (heniedh/eni) =ed (GCEC) get children (for $v in e return (e1, ..., eN))r#[b1,...,bN]
=
0
B B @
for $v in e return (e11, e12, . . . , e1n1,
e21, e22, . . . , e2n2,
· · ·
eN1, eN2, . . . , eN nn)
1
C C A r′
where (ei1, . . . , eini) =get childrenei rij=extract dce
′
ij
r′=r# [b
1.r11, . . . , b1.r1n1,
b2.r21, . . . , b2.r2n2,
...
bN.rN1, . . . , bN.rN nn]
(GCFOR)
get self,get parent::eˆd
→eˆd
get self er=er
get parent er.n=
getExpGlobal(r)
Bibliography
[1] S. Amano, L. Libkin, and F. Murlak. XML Schema Mappings. InPODS, pages
33–42, 2009.
[2] W. Chin. Safe Fusion of Functional Expressions. InProc. Conference on Lisp and
Functional Programming, pages 11–20, San Francisco, California, June 1992. [3] S. Daniels, G. Graefe, T. Keller, D. Maier, D. Schmidt, and B. Vance. Query
optimization in revelation, an overview.Data Eng., 14(2):58–62, 1991.
[4] A. Deutsch, Y. Papakonstantinou, and Y. Xu. The NEXT Framework for Logical
XQuery Opimization. InProc of VLDB, pages 168–179, 2004.
[5] L. Fegaras and D. Maier. Optimizing object queries using an effective calculus. ACM Trans. Database Syst., 25(4):457–516, 2000.
[6] M. Fernamdez, J. Hidders, P. Michiels, J. Simeon, and R. Vercammen.
Optimiz-ing sortOptimiz-ing and duplicate elimination in xquery path expressions. InProceedings
of 16th International Conference on Database and Expert Systems Applications (DEXA 2005), 2005.
[7] A. Gill, J. Launchbury, and S. L. P. Jones. A short cut to deforestation. InFPCA
’93: Proceedings of the conference on Functional programming languages and computer architecture, pages 223–232, New York, NY, USA, 1993. ACM Press. [8] G. Gottlob, C. Koch, and R. Pichler. Efficient Algorithms for Processing XPath
Queries.ACM TODS, June 2005.
[9] T. Grust, M. Mayr, and J. Rittinger. Let SQL drive the XQuery workhorse
(XQuery join graph isolation). InEDBT, pages 147–158, 2010.
[10] T. Grust, S. Sakr, and J. Teubner. XQuery on SQL Hosts. InVLDB, pages 252–
263, 2004.
[11] B. Gueni, T. Abdessalem, B. Cautis, and E. Waller. Pruning Nested XQuery
Queries. InCIKM, pages 541–550, 2008.
[12] J. Hidders, J. Paredaens, R. Vercammen, and S. Demeyer. A Light but
For-mal Introduction to XQuery. InSecond International XML Database
Sympo-sium,(XSym2004), pages 5–20, 2004.
[13] C. Koch. On the role of composition in XQuery. InProceedings of Eighth
Inter-national Workshop on the Web and Databases (WebDB 2005), 2005.
[14] J. Lu, T. W. Ling, C.-Y. Chan, and T. Chen. From Region Encoding To
Ex-tended Dewey: On Efficient Processing of XML Twig pattern Matching. InProc
of VLDB, 2005.
[15] A. Ohori. Representing object identity in a pure functional language. InICDT ’90:
Proceedings of the third international conference on database theory on Database theory, pages 41–55, New York, NY, USA, 1990. Springer-Verlag New York, Inc.
[16] A. Ohori and I. Sasano. Lightweight fusion by fixed point promotion. SIGPLAN
Not., 42(1):143–154, 2007.
[17] W. L. Page, J. Hidders, P. Michiels, J. Paredaens, and R. Vercammen. On the
expressive power of node construction in XQuery. InProceedings of Eighth
[18] P. Parys. XPath evaluation in linear time with polynomial combined complexity.
In J. Paredaens and J. Su, editors,PODS, pages 55–64. ACM, 2009.
[19] I. Tatarinov and A. Halevy. Efficient Query Reformulation in Peer Data
Manage-ment Systems. InProceedings of the ACM International Conference on
Manage-ment of Data, pages 539–550, 2004.
[20] I. Tatarinov, S. D. Viglas, K. Beyer, J. Shanmugasundaram, E. Shekita, and C. Zhang. Storing and Querying Ordered XML Using a Relational Database
Sys-tem. InProc of SIGMOD, 2002.
[21] P. Wadler. Deforestation: Transforming programs to eliminate trees. In
Proc. ESOP (LNCS 300), pages 344–358, 1988.
[22] World Wide Web Consortium. XQuery1.0 : An XML Query Language, January 2007. W3C Recommendation.
[23] World Wide Web Consortium. XQuery1.0 and XPath2.0 Formal Semantics, Jan-uary 2007. W3C Recommendation.
[24] L. Xu, T. W. Ling, H. Wu, and Z. Bao. DDE: From Dewey to a Fully Dynamic
A
Sorting without Duplicates on Extended Dewey Code
In this appendix, we use the standard list representation for the extended Dewey code to simplify our presentation. First, our extended Dewey code(xD) is redefined as follows.
ds::= []|d :ds
d ::=ǫ|nx wheren∈(R ∪ I)
x ::=ǫ|”.”d|”#”ds
To show sorting without duplicates on xD, we define ordering and equivalence relation on xD.
A.1 Ordering on xD
We use≺d and≺x for ordering ond andx, respectively. We define partial order on
xD.
Definition 4 (xD Order).For ordering ond,n1x1≺d n2x2if and only if one of the following three conditions holds;
– n1, n2∈ Randn1=n2,x1≺x x2.
– n1, n2∈ Iandn1< n2.
– n1, n2∈ Iandn1=n2,x1≺x x2.
For ordering onx,
– . d1≺x . d2if and only ifd1≺d d2holds.
– ǫ≺x x1if and only ifx16=ǫholds.
Lemma 2 (Transitivity of xD Order).Ifd1≺d d2andd2≺d d3thend1≺d d3.
Proof. Structural induction ondis used.
We use∼d and∼x for equivalence relation on d andx, respectively. We define
equivalence relation on xD.
Definition 5 (Equvalence Relation).For equivalence relation ond,n1x1∼d n2x2 if and only ifn1=n2andx1∼x x2.
For equivalence relation onx,
– ǫ∼x ǫ.
– . d1∼x . d2if and only ifd1∼d d2holds.
– #ds1∼x #ds2if and only ifds1++ds2issortable.
Definition 6 (Sortable).For given a list of xDds1,ds1is sortable if and only if one of the following three conditions holds;
– ds1= []
– ds1=d1: []
Lemma 3 (Irreflexivity of≺d).≺d is irreflexive from its definition.
Theorem 2 (Reflexive partial order of-).-is a reflexive partial order.
Surprisingly, both duplicate eliminating and merging two xD codes can be defined as the following one algorithm.
Definition 7 (Duplicate Elimination and Merging). Given two xD code n1x1 and
n2x2wheren1x1∼d n2x2, both duplicate eliminating and merging,n1x1⊕dn2x2is defined by the following inference rules;
(x1⊕xx2)→x3
(n1x1⊕d n2x2)→n1x3
(ǫ⊕xǫ)→ǫ
(d1⊕d d2)→d3
(.d1⊕x.d2)→.d3
xDDO(ds1++ds2)→ds3
(#ds1⊕x#ds2)→#ds3
Definition 8 (Sorting without Duplicates on xD, xDDO).For a given list of xDds1 whereds1is sortable, sorting without duplicates onds1(xDDOds1) is defined straight-forwardly by using-and⊕d.